GPT-4o has EQ now

OpenAI just had a release day, with some a live demo, and a blog post with many more video demos of their new flagship model. At a high level, the new model they’re releasing is faster and GPT-4-turbo, and is natively multi-modal (rather than the multi-modality being externally designed by connecting models together). A lot of their demos emphasize the speed of response and the emotional intelligence (both in how it expresses itself, and how it understands instructions). From my limited interactions so far, I do not detect a significant improvement on IQ-type intelligence. I’ll wait for further benchmarks to come out to give my final judgement here, but my overall impression is that this is a release that’s focused on multi-modality, performance, and EQ.
Multimodality
In AI systems, multi-modality is the holy grail. When I was working on self-driving cars, that was also the dream architecture: one big model that takes in all of the sensors as inputs (sound, visual, lidar, radar) and makes decisions directly. For technical reasons, this is really hard to do (compute limitations, training dataset limitations, model size limitations), so most AI systems tend to build modal-specific models and then orchestrate them together.
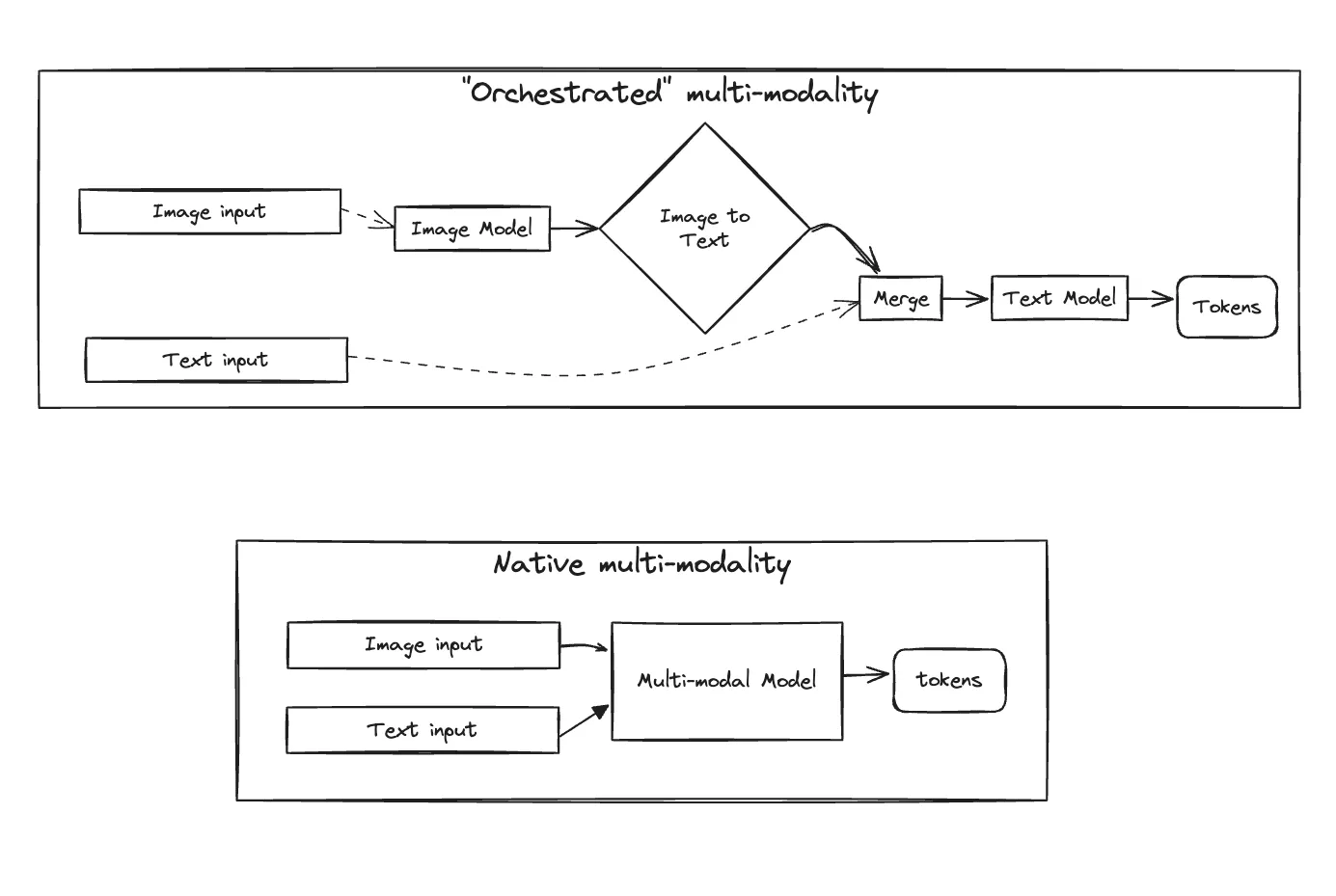
That was also my understanding of what GPT-4 and previous openAI models used to do when you passed it an image. This release marks a change: they claim that the model has now been trained directly on multi-modal data and that’s why it can analyze and react to video and sound in a significantly faster and more accurate way. If this is true, this is a big deal! It’s of course hard to know since openAI is very much not open, but I think that’s what’s happening.
They spend a lot of time on demos that showcase this new strength: real-time translations, tutoring on math problems, reacting to what people are wearing or what’s going on in the scene. They also spend a lot of time interrupting the audio from the AI, and the responsiveness is impressive. It’s not human-like yet (remember humans can read more cues than just audio for when people want to interrupt, like a mouth opening or someone leaning in), but it’s trending in the right direction. This makes assistant use-cases really powerful right off the bat, without any wrapper required.
Another big and impressive feat of the multi-modality is that it seems that the AI will be easier to control when creating art concepts. If you’ve tried to create specific AI art for your company (say, something with your logo on it, or some text) you’ve likely been very frustrated: it does not work well to start with, and doesn’t really have good iteration built-in, so it’s very hard to slowly make something better to the point where you want to use it. Progress in this area has been made, as the screenshot (from their release blog post) beneath shows.
Emotional Intelligence
A very big focus of this release is the EQ of the models. Like many people are commenting online, openAI is very very close to releasing her.

Examples of the EQ capabilities include getting the AI to be sarcastic, to sing, to add lots of drama (with nuanced levels!) while telling a story. In addition, there is better EQ understanding capabilities (what is the person feeling, what’s their tone / face transpiring, what is their body language). They also show a lot of singing, and like most humans, the AI sucks at singing by default. It does a little better if you ask it to sing happy birthday, but clearly the singing training set was not filled with good musicians yet.
Making progress on the EQ is really exciting, and will improve the consumer aspects of the openAI product. Given that their mission is AGI however, I think it’s quite revealing: if they could make the AI superhuman intelligent they would be doing that right now. Not releasing big IQ updates means the reasoning side of intelligence is hitting diminishing returns, and we’re likely hitting the top of an S curve with current architectures. Companies like openAI are focusing on UX, performance, and adjacent forms of intelligence (like EQ).
UX brilliance
OpenAI is the ones that came up with the chat UX on top of token-generating models. That small UX trick made GPT-3 go from an unknown area of interest for very specialized researchers to a consumer product with 100M users in less than 2 months. That’s really insane, and a testament to the importance of UX: clever UX tricks have no moat, but are transformative for everyone (see also keyboard and mouse to control the computer).
I believe chatGPT came up with another piece of UX brilliance today, that was not particularly emphasized. They are launching a chatGPT desktop app, and the big advantage that this provides is that they get easy access to full screen share. This means that the AI can be permanently looking at what you’re doing (let’s ignore some bandwidth challenges for a second, these can be fixed with frame throttling).
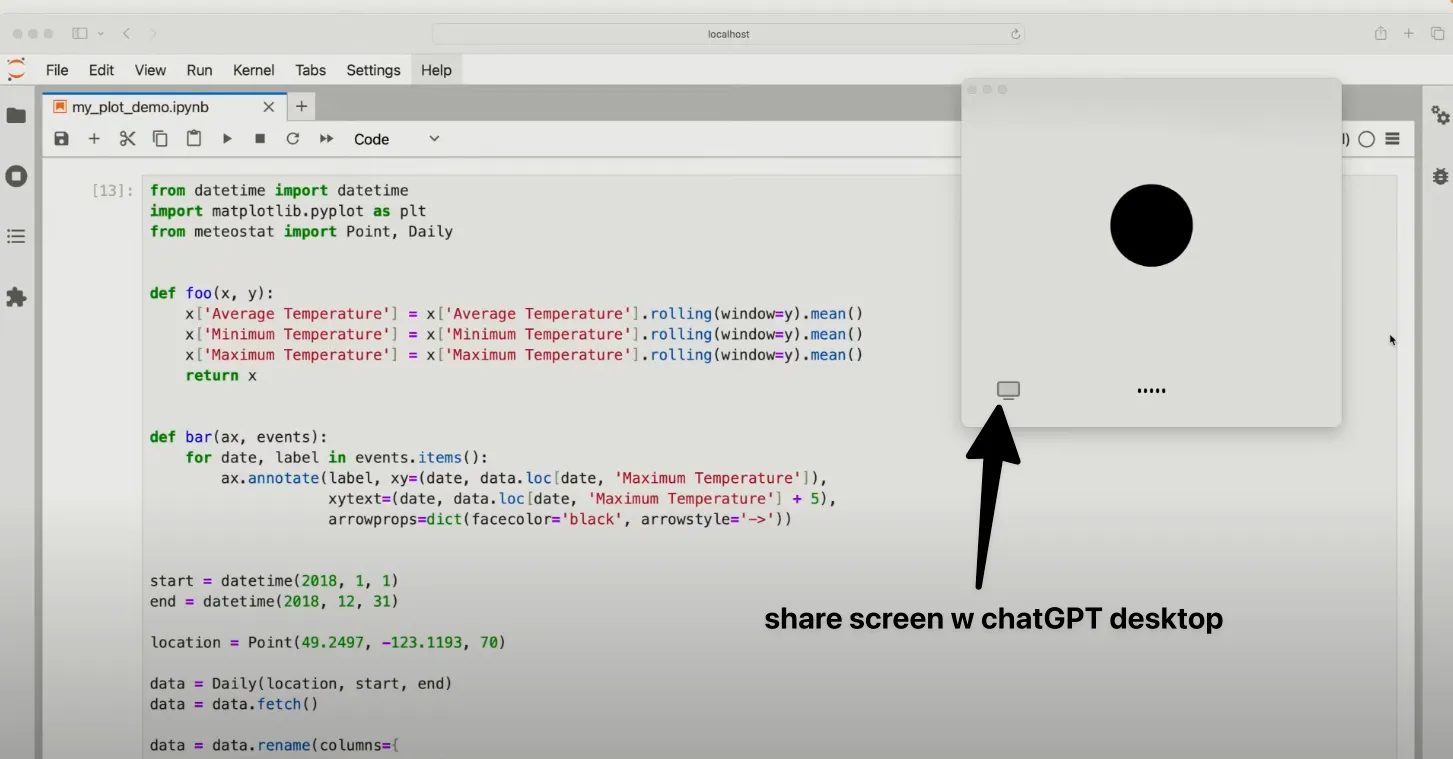
This is obviously the UX that you want for an AI that’s helping you work on a computer. It’s like pair programming, or pair anything-ing, it’s the most natural and powerful way to get real-time advice on the task at hand.
I wouldn’t be surprised to see this pattern lead to some very cool new automation tools.
Another very important piece of the UX is the responsiveness speed increase. It’s critical to be able to interrupt and get answers quickly, otherwise people lose patience and interest. Sam highlights this in his article that he published today, and I agree with him. I’ve been chatting with chatGPT while walking my dog, and constantly get frustrated at the interruptions and latency before the answers.
Meta opinion: the event
OpenAI is killing it for their announcements. They manage to package something exciting, release it in a polished way, without going over the top (see Apple and their events for a thinner iPad), whilst remaining very real about the limitations.
Every video demo available on their page doesn’t go perfectly, but gives the viewer a very authentic and real feeling about the new capabilities. This is the opposite of what google did with their over-produced release of the multi-modal gemini models.
OpenAI is good at PR.